


Ich verstehe. Habe mir comfy kurz angeschaut, das ist quasi das Tool was die Images erstellt.
Nicht ganz. ComfyUI bietet die Umgebung dafür. Die Bilder werden von dem jeweiligen Modell via Prompteingabe generiert. Das UI von ComfyUI wird dabei über den localhost Port 8188 im Browser aufgerufen. Dort kann man sich dann eben Workflows zusammenklopfen oder diese auch online herunterladen, wobei sie eben auf vielen Websites als JSON-Datei angeboten werden, die man dann einfach nur in dieses Browserfenster ziehen muss.
Hier wäre beispielsweise ein simpler Workflow für Stable Diffusion 3 Medium:
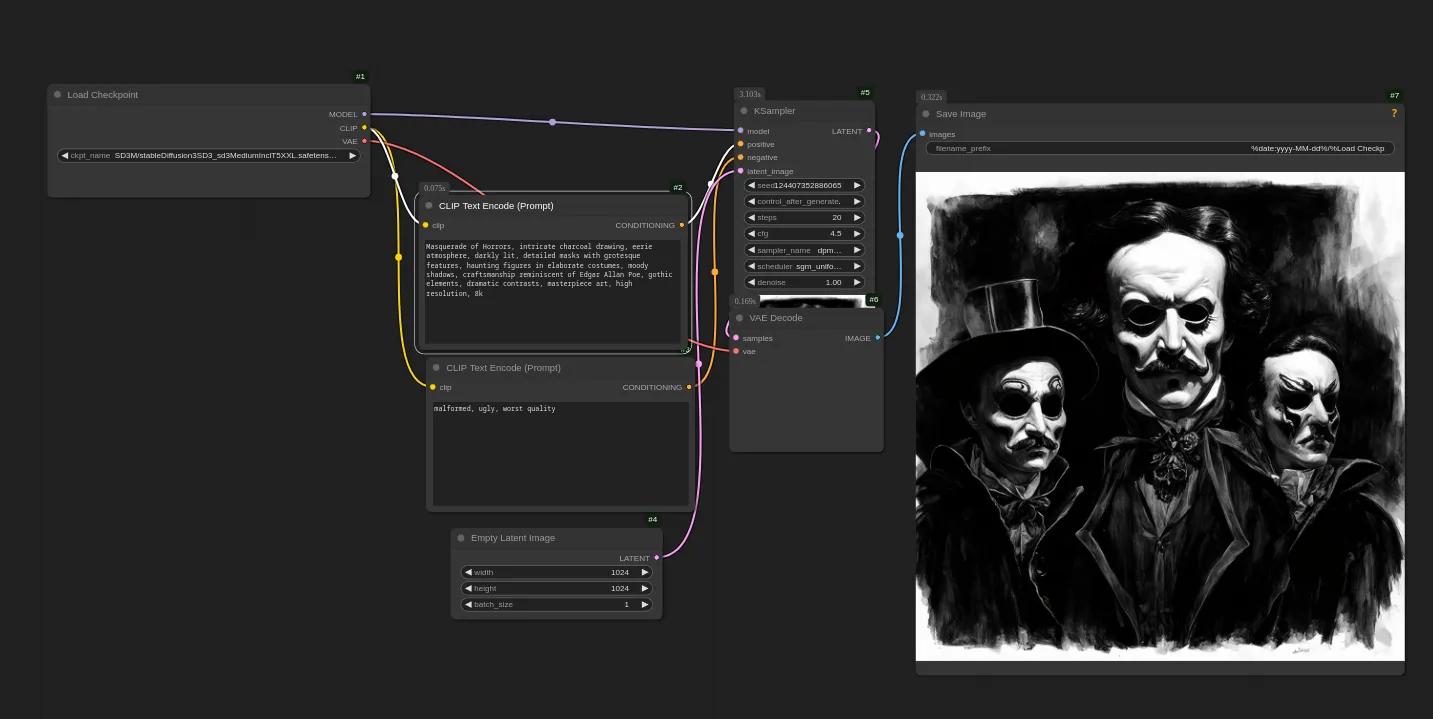
Das Ganze kann man sich auch einfacher machen, indem man einfach Forge oder A1111 nutzt. Allerdings bietet ComfyUI zwei Vorteile gegenüber diesen WebUI's.
Zum einen kann man sich dort auch ziemlich aufwendige Workflows zusammenbasteln, die eben nicht nur Bilder generieren, sondern diese auch weiterverarbeiten.
Hier wäre beispielsweise ein Workflow, den ich vor ein paar Wochen gebastelt habe:
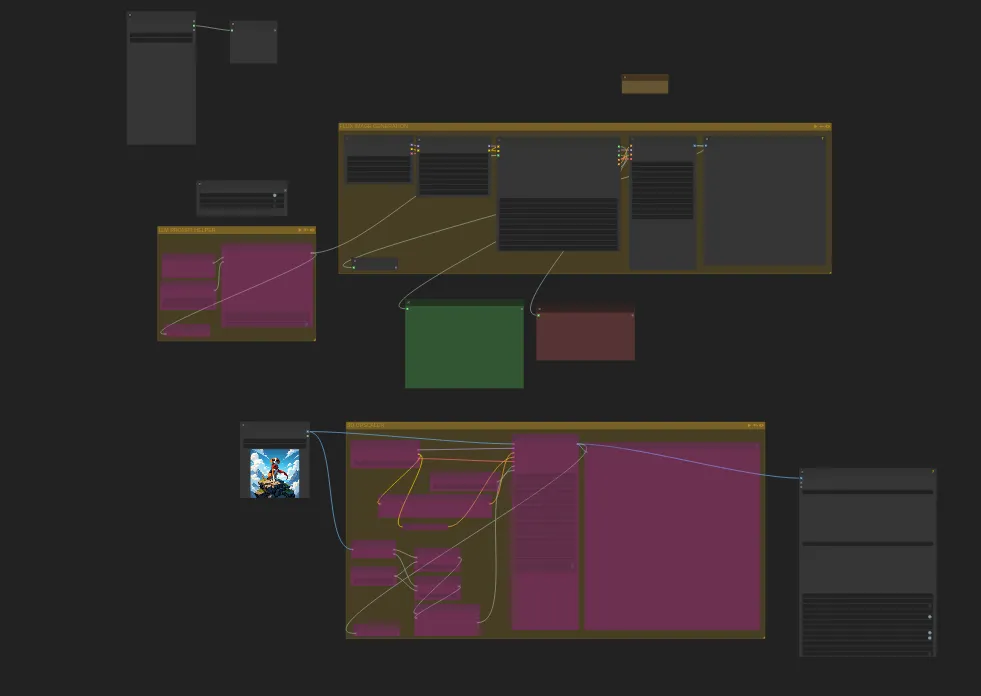
Das sieht man jetzt nicht, da ComfyUI den Text in den Nodes nicht mehr anzeigt, wenn man zu weit hinauszoomt, aber dieser Workflow beispielsweise (sofern alle Groups aktiviert sind), erstellt erst einen per LLM generierten Prompt, leitet diesen dann an Flux weiter, wo diesem noch zuvor festgelegte Style-Prompts beigefügt werden. Anschließend generiert Flux dieses Bild. Fertiggeneriert wird das Bild dann weiter an einen SDXL Upscaler weitergeleitet. Das Endergebnis wird dann im JPEG-Format abgespeichert.
Das ist so eine der stärken von ComfyUI. Diese ganzen Aufgaben können hier eben mit einem Knopfdruck erledigt werden. Diesen Workflow könnte man auch noch erweitern oder einzelne Nodes durch andere Tauschen.
Der weitere Vorteil ist, dass man solche Workflows eben als JSON abspeichern kann. Dieses JSON kann man dann mit beispielsweise Python öffnen und auf einzelne Keys zugreifen und deren Inhalt ändern, wie den Key, der den eigentlichen Prompt enthält.
Möchte ich dann in meinem Projekt ein Bild generieren, bekommt ComfyUI nicht nur den Prompt zugeschickt (also das, was ich generiert haben möchte), sondern immer den kompletten Workflow als json. Auf diese Weise kann ich dann auch unterschiedliche Workflows mit einer Anwendung nutzen, wie bei mir der eine Workflow zum Generieren der Filmposter und der andere, der die Beschreibungstexte erzeugt.
ComfyUI muss dafür dann zwar laufen, aber eben nicht im Browser geöffnet sein.





