

Ahhh! Damit kann man zB sowas lösen wie Datum Uhrzeit für gewisse Benutzer zB in einem anderen Format anzeigen weil es vielleicht zB user aus den USA sind? Oder für den Euro in der EU?
Beiträge von PixelPatron
-
-
Was genau ist denn feature flag? Habs scgonmal gehört...
-

Schrei nicht so! Und nein danke!!!
JETZT ERST RECHT
 Spass
Spass 
-
-
Puh. Die ganzen job Angebote nerven übel.
-
Was geht bei euch so? Mal Horchen
bin grad weniger am PC da ich sehr viel Zeit mit meinen Söhnen verbringe. Der mittlere hat jetzt mit 4 Jahre die Diagnose A typischer Autismus bekommen. Schweres Thema aber es gibt echt gute Bücher zu dem Thema. Kennt jemand einschlägige Foren zu dem Thema vielleicht? -
Ich selber habe mit Python nichts am hut
Aber chatgpt sieht das ganz klar:
ZitatAlles anzeigenDer Fehler tritt auf, weil eine Datei oder ein Stream Zeichen enthält, die nicht korrekt als UTF-8 interpretiert werden können. Der Byte 0xfc entspricht „ü“ im Latin-1-Encoding, wird aber in UTF-8 nicht als gültiger Start-Byte erkannt.
Mögliche Lösungen:
1. Explizites Encoding angeben
Falls du eine Datei öffnest, versuche ein anderes Encoding, z. B. latin-1 oder windows-1252:
Alternativ kannst du das Encoding errors='ignore' setzen, um fehlerhafte Zeichen zu überspringen:
2. Datei-Encoding überprüfen
Falls du unter Linux arbeitest, kannst du mit file oder chardet das Encoding prüfen:
Oder mit Python:
Codeimport chardet with open('datei.txt', 'rb') as f: result = chardet.detect(f.read()) print(result['encoding'])3. Binary-Read und Umwandlung versuchen
Falls du das Encoding nicht kennst:
Das ersetzt ungültige Zeichen mit � statt den Fehler auszulösen.
Lass mich wissen, falls du mehr Details brauchst!
-
Hey! You are welcome!
The community is active in its own way. There are some gems and plenty of know-how here
-
Die Frage war: Wie gestaltet ih den checkout Prozess? Aber das hat sich nun erledigt das ivh selber einen weg gefunden habe.
User Credits ist eine virtuelle Währung sie sich der user durch Aktivität oder events verdienen kann.
-
Hi,
leider alles lokal.
Ich bin jetzt weit zurückgerudert und das ist jetzt der aktuelle Stand:
User nimmt waren -> warenkorb -> checkout -> daten checken .. waren übersicht anzeigen .. und dann bestellung platzieren ..

Was mir aber jetzt wieder fehlt ist die sache mit dem payment .. sprich diese geschichte mit den User credits .. wie am besten implementieren?
Sprich user geht in den checkout, füllt alles aus wenn nötig, select mit payment Methoden, je nach Art der Bezahlung vor dem submit der bestellen prüfen ob user credits oder Bank transfer gewählt wurde:
User credits
Checken ob genug credits, Abzug der credits -> confirm success
Wenn zu wenig credits dann kommt ne message und er bleibt auf der Seite und muss was anderes zur Bezahlung wählen.
Bank transfer:
Direkt confirm success mit bankdaten und Details zur order.
Was ich mir aber auch schon gedacht habe .. die user haben ja ein eigenes panel .. sollte sie nachdem sie die bestellung gemacht haben dorthin gehen und quasi das bezahlen hier erledigen? ...
PS: Die Handynummer gibts nicht mehr
-
Moin meine liebstes Forum,
(ich finde ein stumpfes Hi zu langweilig.)
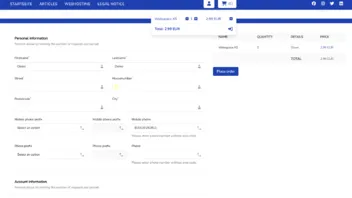
Ich Sitze ja aktuell an dem ecommerce Part meines CMS'es (sagt man das so?) und habe Probleme dabei eine richtige Struktur bzw den richtigen Weg zu finden.
Bisher habe ich:
Warenkorb
Der Nutzer / Gast kann Produkte einlegen und auch die Mengen ändern, Produkte aus dem Korb löschen. Ich habe den Warenkorb als Component in die Navigation gepackt. Aktuell gibt es keine eigene Übersicht, der Benutzer kann im Checkout sehen was er eingepackt hat. Es können generell Gäste sowohl als auch User Produkte in den Warenkorb legen einzigster Unterschied das der Gast im Warenkorb Components einen Hinweis hat das er sich einloggen/registrieren muss für den Checkout.
Ist das so gut oder sollte ich eher nur angemeldeten Usern erlauben den Warenkorb zu nutzen? Problematisch ist bisher nur die Übergabe des Korbes vom Gast zum User.
Checkout:
Ein simples Step Form mit einzelnen schritten, ebenfalls ein Livewire component.
Der erste Step ist die Übersicht des Warenkorb.
Der zweite Step ist der Abgleich der Userdaten wie Adresse Name und Telefonnummer, E-Mail.
Der 3te Step ist die Wahl der Payment Methode und ab da hackt es: Der Nutzer kann aktuell zwischen Credits (Testphase) und einer einfachen Bankünerweisung wählen.
Wenn Banküberweisung gewählt kann der Nutzer direkt zur Bestätigung. Wenn er credits wählt muss ich dann direkt prüfen ob er genug hat .. Wenn nicht gehts nicht weiter bzw er muss eine andere payment Methode wählen. Sollte der user genug credits haben werden die credits abgezogen und er kann weiter zu Konfirmation. Bei der erfolgreichen Zahlung der Bestellung ändeet sich der status der order zu success.
Wie müsste das ganze mit zB PayPal aussehen? Ich denke Anfrage schicken -> success -> confirmation oder eben -> fail und back zu step 3 eine andere Methode wählen?
Der 4te step ist Quasi die Bestätigung und der Überblick über alle gekauften Produkte und die komplette Summe plus gewählte payment Methode. Bei der Methode banküberweisung sollten die bankdaten von mir kommen.
Macht das Sinn? Habt ihr Verbesserungen? Ich habe Angst das ich was vergesse.
-
Wenn ein echter Browser zur Verfügung steht.... Wieso nicht einfach Repo in GitHub öffnen, und . drücken?
Den Trick kennt vlt hier niemand aber bisher

LOL! Kannte ich tatsächlich noch nicht!
-
Also ich selber nutze auch oft das Handy und habe bisher leider nichts gutes finden können.
Es gibt:
https://apps.apple.com/us/app/runesto…or/id1548193893 -> ist ganz ok und reicht für das meiste eigentlich aus!
https://apps.apple.com/us/app/koder-code-editor/id1447489375 -> eher darauf ausgelegt wenn du zb files auf dem Handy hast also local arbeitest. Dabei spielt es keine Rolle ob du das per webdav oder ftp oder sonstwas holst .. -> ok!
https://apps.apple.com/us/app/code-ed…de/id1581290510 -> schrott!
https://apps.apple.com/us/app/visual-code/id6444809156 -> ok!
Ich persönlich nutze
 Working Copy - Git clientAccess Git repositories on the go. Clone, edit, commit and push while allowing other apps access to repositories. Git is a important part of our work-life…apps.apple.com
Working Copy - Git clientAccess Git repositories on the go. Clone, edit, commit and push while allowing other apps access to repositories. Git is a important part of our work-life…apps.apple.comund bis auf das Optische .. (manchmal ist einfach chaos) funzt das erstaunlich gut. Finde für das arbeiten an REPOS bisher das beste.
Aber ganz ehrlich: Nichts ersetzt die IDE am PC .. schnapp dir ein Netbook .. das ja ganz klein und zauber dir ein schönes Linux drauf und VSCODE oder Intelij
Thema Web IDE kenne ich nur VScode Server -> hier mal nen VIdeo von nem coolen dude der das ganz gut erklärt und zeigt:
Externer Inhalt www.youtube.comInhalte von externen Seiten werden ohne Ihre Zustimmung nicht automatisch geladen und angezeigt.Durch die Aktivierung der externen Inhalte erklären Sie sich damit einverstanden, dass personenbezogene Daten an Drittplattformen übermittelt werden. Mehr Informationen dazu haben wir in unserer Datenschutzerklärung zur Verfügung gestellt.eventuell wäre das noch was: https://github.com/features/codespaces
-
ok. Naja besser machen was schon gut ist war nie eine gute Idee.
-
Laravel 12 jetzt anpassen möchte und auch TailwindCSS 4.
Gibts gravierende Änderungen?
-
Hat schon mal jemand spaßeshalber neun shop programmiert? Was für Funktionen sollte / muss es geben?
-

Also noch nicht aber würde gerne die Discord Bots damit laufen lassen und hoffentlich kriege ich das so eingestellt, dass wenn ich in github eine Änderung pushe der Bot mit dem neuen Code sich neustartet mal sehen
Also wenn das nicht geht fress ich nen besen
-
Also heute is porno. Sitze grad mit Kaffee und kippe auf dem Balkon. Wind könnte wärmer sein ABER die Sonne ist gut
-
Okay ich verstehe. Eine wichtige Frage habe ich aber noch: Hast du generell deine Models so aufgebaut das du Downloads anbieten könntest? Sprich: Der Image Upload .. -> file Model hast du da für Images eine Tabelle und zb eine für Files wie pdfs?
Nachtrag:
HasImages
PHP
Alles anzeigen<?php namespace App\Filament\Resources\Traits; use Filament\Forms\Components\FileUpload; use Illuminate\Support\Facades\Storage; trait HasImages { public function getFolderUrlAttribute(): string { return $this->files()->exists() ? Storage::url('public/files/folder/' . $this->files()->first()->filename . '.webp') : $this->defaultImage(); } public function getPreviewUrlAttribute(): string { return $this->files()->exists() ? Storage::url('public/files/large/' . $this->files()->first()->filename . '.webp') : $this->defaultImage(); } public function getImageUrlAttribute(): string { return $this->files()->exists() ? Storage::url('public/files/show/' . $this->files()->first()->filename . '.webp') : $this->defaultImage(); } public function getImageContactAttribute(): string { return $this->files()->exists() ? Storage::url('public/files/contact/' . $this->files()->first()->filename . '.webp') : $this->defaultImage(); } protected function defaultImage(): string { return Storage::disk('public')->url('default.webp'); } public static function formImagesField(): FileUpload { return FileUpload::make('images') ->label('Upload Images') ->helperText('Upload multiple images') ->multiple() ->disk('public') ->directory(fn(\Filament\Forms\Get $get, $record) => strtolower(class_basename($record)) . '/' . $get('id') . '/images/') //->acceptedFileTypes(['image/*']) //->maxSize(10240) ->storeFilenamesIn('original_name') ->visibility('public') ->previewable(false) ->reactive() ->columnSpan('full') ->saveRelationshipsUsing(function ($component, $state, $record) { foreach ($state as $filePath) { $record->files()->create([ 'path' => $filePath, 'model' => get_class($record), 'original_name' => 'aasd', ]); } }); } }Bin total lost: Als Fehler bekomme ich beim Uploaden:
SQLSTATE[HY000]: General error: 1 table files has no column named article_id (Connection: sqlite, SQL: insert into "files" ("path", "article_id", "updated_at", "created_at") values (article/1/images//01JPJVHQYRYPKFP8S40VYJ5D1N.jpg, 1, 2025-03-17 21:08:31, 2025-03-17 21:08:31))
Wobei ich nicht will das da article_id steht oder geht das nicht anderster?
-
Was ich meinte in dem Trait finde ich nur das der filename und Endung gespeichert werden. Wo deklarierst du den Rest oder bin ich einfach grad nur blind?
Macht es Sinn in den Trait upload Funktion zu bauen die ich quasi nutze um images hoch zuladen?