Tag.
Ich melde mich damit wieder aus der Versenkung zurück. Kurz nach der Anmeldung hier, hatte sich irgendwie so ein Drang gebildet, möglichst viel zu Posten bzw. zu schreiben. Dann verursachte das Stress und ich habe den Stecker gezogen. Sollte dieses Projekt / dieser Irrsinn aber tatsächlich jemanden interessieren, dann tut es mir leid für die Funkstille.
Eine Weile lang hatte ich überlegt, dieses Projekt an den Nagel zu hängen. Allerdings hat mich die Sache dann doch nicht mehr so recht losgelassen. So wie ich das damals aufziehen wollte, hätte das hier und da zwar funktioniert, aber das Endergebnis oder besser gesagt Beschreibungstexte und Bilder wären häufig nicht sonderlich brauchbar gewesen. Deshalb habe ich mich dann vor einer Weile dazu entschieden, die Sache ganz anders anzugehen.
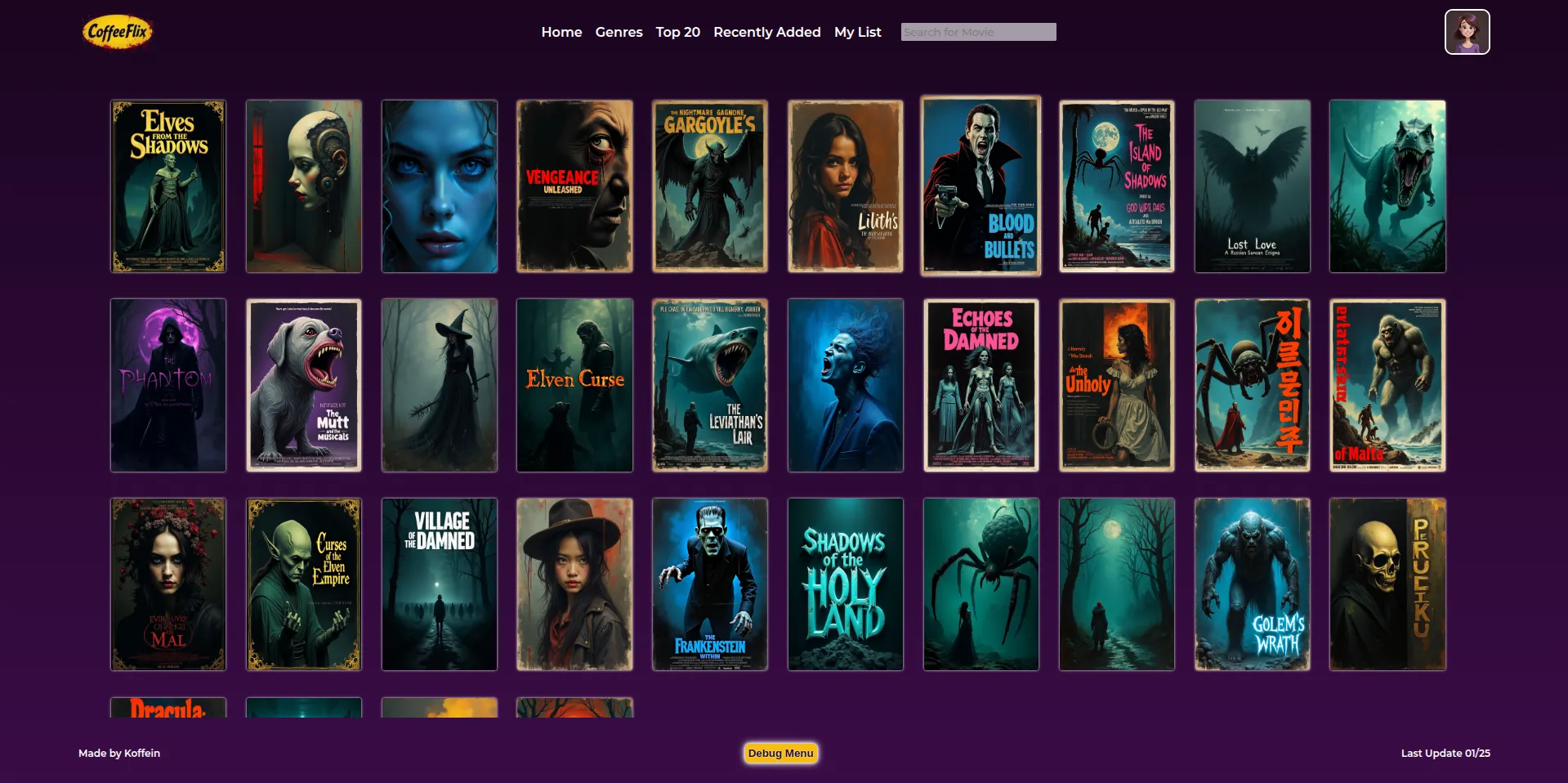
Statt also den kompletten Weg zur jeweiligen Film-Page (Cover-Art, Schauspieler, Beschreibungstext und Co.) zu automatisieren, wollte ich einen kuratierten Ansatz angehen. Ich werde daher sämtliche Beschreibungen - mal länger, mal kürzer - selbst schreiben. Außerdem wird jedes Bild manuell generiert. Später kam ich nämlich auch auf den Trichter, dass jede Film-Page auch Screenshots von Szenen beinhalten soll, wie man das von Amazon her kennt. Das ist zwar nicht (mehr?) innerhalb von Prime Video, aber auf den Pages für DVD's und Blurays sieht das noch so aus.
Beispiel:

Schauspieler werden daher eben nun auch nicht mehr zufällig generiert, sondern kommen aus einem Pool an LoRAs, die ich im Vorfeld trainiere (kleinere Rollen/Statisten nicht inbegriffen). Noch ist dieser Pool sehr überschaubar. Im Moment bin ich bei 12 fiktiven Personen. Um eine Person zu erstellen, nutze ich Charakter-Editoren diverser Videospiele. Für den Datensatz mache ich dann Screenshots, die diesen Charakter innerhalb von verschiedenen Szenen und in unterschiedlichen Posen, Winkeln und Belichtung zeigen. Das Training darf nicht zu lange dauern, da der Charakter dann zwar ähnlicher wird, aber zunehmend in dem Stil des Spieles (als stilisiertes 3D-Modell) generiert wird. Außerdem müssen GUI-Elemente und Dinge wie Lebensbalken ausgeblendet werden. Deshalb eignen sich vor allem Spiele mit Fotomodus.
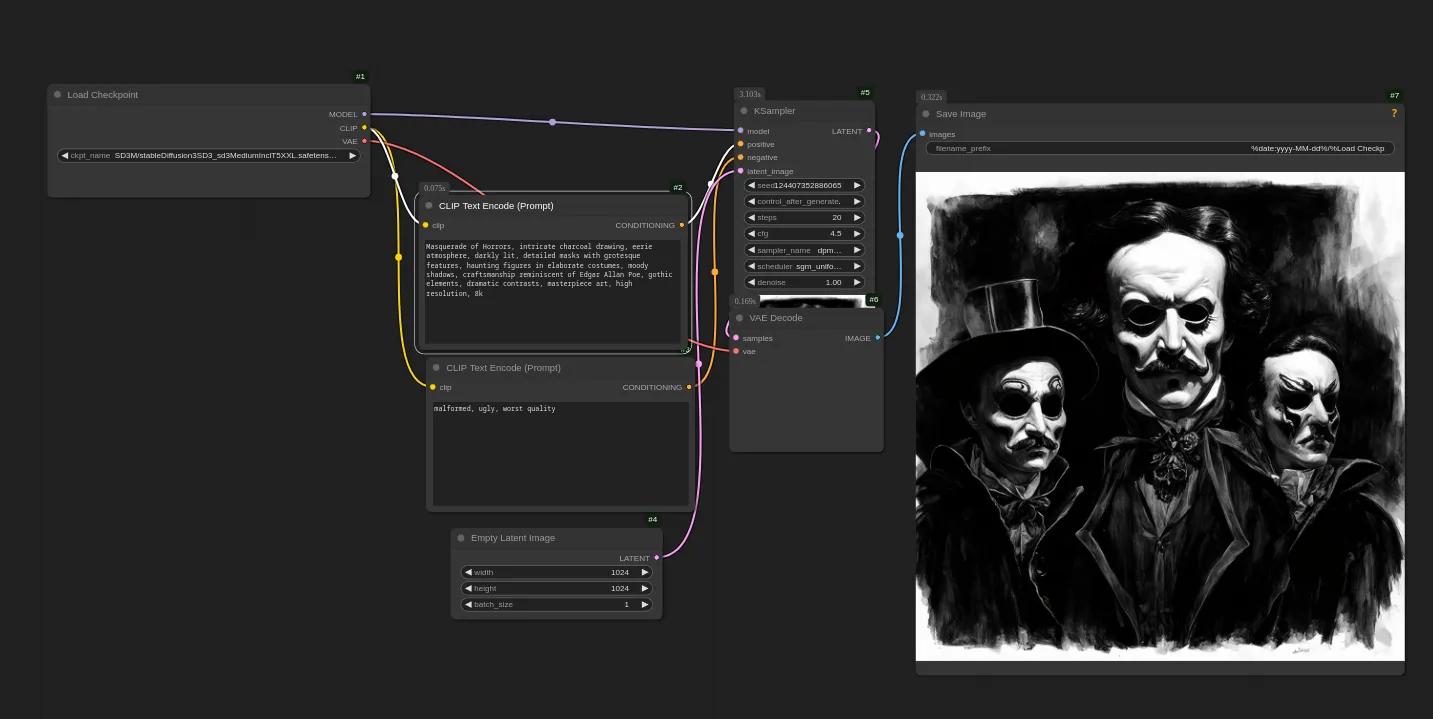
Einer der Screenshots die für's Training genutzt wurden (aus Baldur's Gate 3):

Sample-Bild aus dem Training (Step 700):

Gerade aufgrund von diesem neuen Ansatz, musste ich die ganze Idee stark abändern. Es sollte am Ende nämlich immer noch möglichst glaubhaft wirken. Mir ist allerdings aufgefallen, dass es bei mehreren Schauspielern in einer Szene oder auf einem Cover schnell mal zu Problemen kommt. Eine Style-LoRA + eine Charakter-LoRA zwicken sich häufig nicht wirklich. Die Sache sieht aber anders aus, wenn man mehrere Charakter-LoRAs reinlädt. Da hilft es dann auch häufig nicht viel, die Gewichtung der einzelnen LoRAs ein wenig anzupassen oder sehr lange und explizite Prompts zu schreiben. Bei einem Versuch, drei Charaktere in einer Szene unterzubringen, wurden fast ausschließlich dreimal die gleiche Person generiert, wobei das Gesicht ein Mix aus allen dreien war. Ich kam aber dann auf die Idee, das jeweilige Bild initial nur mit einer Charakter-LoRA zu generieren und die anderen Personen nur vage so beschreibe, wie die anderen Schauspieler aussehen (Größe, Statur usw.). Im Nachhinein nutze ich dann einfach die Inpainting-Funktion von Forge, maskiere den Kopf und lass bei der Person - eben dann mit der jeweiligen LoRA geladen - einfach das Gesicht dieses Schauspielers generieren. Das klappt relativ gut, aber es sind häufig mehrere Versuche nötig. Schon deshalb würde der anfängliche automatisierte Ansatz nicht funktionieren.
Der Plan sieht so aus, dass ich wohl einen ganzen Haufen an fiktiven Schauspielern auf diese Weise erzeugen werde. Eine genaue Zahl habe ich hier nicht festgelegt, aber es könnten ein paar hundert werden. Bei Charakter-LoRAs reicht eine kleine Dimensionierung. Daher nehmen die auch nicht viel Platz auf der Platte weg (zweistelliger MB-Bereich). Für Szenen, Cover etc. werde ich dann noch einzelne Style- und Konzept-LoRAs trainieren.
Hier ein paar Beispiele der Horror-Cover-LoRA, die nach etlichen Fehlschlägen dann doch brauchbar wurde:



Während der letzten Wochen habe ich zwar wieder etwas mehr trainiert, bin aber auf kühles Wetter angewiesen. Meine GPU heizt gut beim Training und wenn es heiß wird, staut sich die warme Luft in der Wohnung ohnehin schon. Läuft das Ding dann auch noch mehrere Stunden bei nahezu 100%, dann ist es ein wenig so, als würde ich zusätzlich zu den hohen Temperaturen auch noch die Heizung anwerfen.
Mist habe ich beim Training viel gebaut. Auch das ein oder andere, das sich anfangs wie eine super Idee angehört hat, entpuppte sich letztendlich als völliger Griff ins Klo. Ich schätze aber mal, so lernt man dazu. Das Ding ist und bleibt am Ende letztendlich nur so etwas wie ein beklopptes Kunstprojekt, in das ich insgesamt wohl mehr Zeit und Energie stecken werde, als notwendig ist. Ich arbeite nur sporadisch daran, also kann das noch sehr lange dauern. Sollte allerdings Interesse an einer Beispiel-Page für einen Film bestehen (gerne auch mit Vorschlag zu Genre, Setting und Titel), werde ich da etwas zusammenbasteln und im Laufe der Tage mal ein paar Screens posten oder die Seite auf Github-Pages packen.